Introduction
Modern data teams face a familiar challenge: business data sits in dozens of disconnected systems — CRMs, data warehouses, SaaS apps, databases — making it nearly impossible to get a single, trustworthy view. Organizations now manage between 101 and 275 SaaS applications on average, while poor data quality costs at least $12.9 million annually.
Data integration directly addresses that fragmentation — but choosing the wrong approach leads to slow pipelines, unreliable reporting, and wasted engineering effort. This article breaks down the most widely used types of data integration, when each one is the right fit, and the best practices that separate effective implementations from costly, unreliable ones.
Key Takeaways
- Data integration combines data from multiple sources into a single, queryable source for analysis and decisions
- Main types include ETL, ELT, Change Data Capture (CDC), Data Virtualization, and API-Based Integration
- ETL and ELT work best for batch analytics; CDC enables real-time syncing; virtualization lets you query data without moving it
- Matching the right approach to your data volume, latency needs, and team skills prevents costly rework down the line
- Strong integration relies on clear data ownership, healthy pipeline monitoring, and analysis grounded in governed data models
What Is Data Integration?
Data integration is the process of collecting data from multiple, often varied sources — structured databases, SaaS platforms, flat files, APIs — and combining it into a single, consistent dataset that is accessible for analysis or operational use.
This isn't just about moving data. Integration involves reconciling different formats, schemas, and update frequencies so that downstream consumers — analysts, dashboards, AI tools — are working with clean, trustworthy information.
Without it, teams pull from contradictory reports and spend approximately 38% of their time on data wrangling instead of generating insights.
Treated as ongoing infrastructure rather than a one-time fix, data integration is what makes every downstream decision — from executive dashboards to AI-driven analysis — actually trustworthy. The different approaches to achieving that are where things get interesting.
Why Data Integration Matters for Modern Teams
Poor integration creates siloed data that causes contradictory reports, slow decision cycles, and analytics that can't be trusted. Data teams spend a disproportionate share of their time cleaning and reconciling data rather than generating insights.
Effective integration gives every team a single source of truth — consistent metrics, faster reporting, and a foundation that supports AI-powered analytics. Tools like Sylus, which let teams query all their business data in plain English, only work reliably when that underlying data is properly integrated and governed through frameworks like dbt models and documentation.
Choosing the wrong integration approach creates technical debt that compounds quickly. Two patterns cause the most damage:
- Over-engineering simple pipelines — adds maintenance burden without meaningful performance gains
- Under-investing in real-time needs — forces teams to make decisions on stale data, eroding trust in analytics
Types of Data Integration
There is no single "correct" type of data integration. The right choice depends on how frequently data changes, where it needs to go, how much transformation is required, and what the downstream use case is.
ETL (Extract, Transform, Load)
ETL extracts data from source systems, transforms it (cleaning, reshaping, enriching) in a separate processing layer, and then loads it into a destination such as a data warehouse. It is the oldest and most established integration pattern.
How it differs: Transformation happens before the data lands in the warehouse, meaning the destination always holds clean, structured data. This is distinct from ELT, where raw data lands first.
Best suited for:
- Organizations with strict data quality requirements before loading
- Complex transformation logic that can't run in-warehouse
- Legacy systems that can't handle in-warehouse compute
Key strength: Predictable, auditable pipelines with well-governed output data.
Main limitation: Can be slow to adapt when source schemas change, and transformation bottlenecks can add latency.
ELT (Extract, Load, Transform)
ELT is a modern variant where raw data is extracted and loaded directly into a cloud data warehouse (e.g., Snowflake, BigQuery, Databricks) first, with transformations applied afterward using SQL-based tools like dbt.
How it differs: The data warehouse handles transformation using cloud-scale compute. This flips the ETL order and removes the intermediate transformation layer.
dbt Labs reports over 50,000 teams using their transformation framework weekly, making it the de facto standard for ELT transformations.
Best suited for:
- Cloud-native data stacks
- Large data volumes
- Teams that prefer version-controlled, code-based transformations
Key strength: Faster raw data ingestion, scalable transformations, and tight integration with the modern data stack.
Main limitation: Requires strong SQL skills and can become expensive if transformation queries are poorly optimized in cost-per-query warehouses.
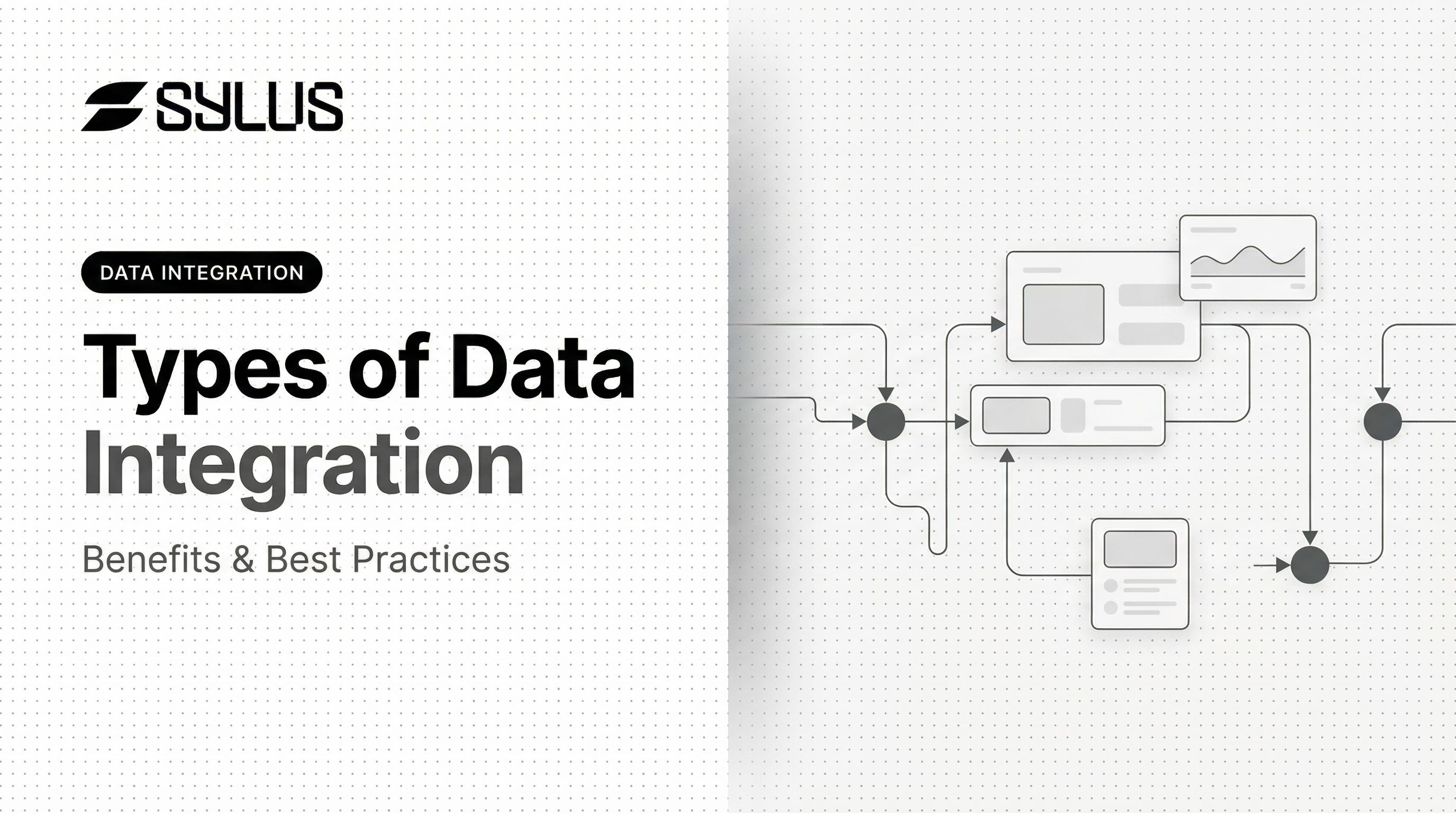
Change Data Capture (CDC)
CDC continuously monitors a source database for row-level changes (inserts, updates, deletes) and propagates only those changes to the destination. Rather than reprocessing entire tables, it moves only what is new or modified.
How it differs: Unlike ETL/ELT which typically run on a schedule (hourly, daily), CDC operates near-continuously by reading database transaction logs, making it the only integration type suited to sub-minute data freshness requirements.
Best suited for:
- Real-time or near-real-time data requirements
- Operational dashboards
- Fraud detection
- Live inventory systems
- Event-driven architectures
Key strength: Low system load (moves minimal data), high data freshness, and efficient use of bandwidth.
Main limitation: Requires database log access (not always available), and setup complexity is higher than batch approaches.
Data Virtualization
Data virtualization creates a unified, virtual data layer across multiple source systems without physically moving or copying the data. Queries are run against a virtual schema that maps to the original sources in real-time.
How it differs: No ETL pipeline, no data warehouse copy — the data stays where it lives and is accessed on demand. This is distinct from all other integration types.
Best suited for:
- Environments where data sovereignty or compliance prevents copying data
- GDPR and PIPEDA compliance scenarios
- Fast access to a unified view without building a full pipeline
Key strength: No storage duplication, instant access to source data, and reduced pipeline maintenance.
Main limitation: Query performance depends entirely on source system availability and can introduce severe latency; not suitable for heavy analytical workloads.
Application/API-Based Integration
This type connects applications directly through their APIs. Data flows between systems (CRMs, marketing platforms, ERPs, payment processors) via pre-built or custom API connectors, often in real-time or near-real-time.
How it differs: Rather than ingesting data into a centralized warehouse, this type enables live, bidirectional data exchange between operational systems — the focus is keeping operational systems synchronized, not feeding an analytics pipeline.
82% of organizations have adopted API-first strategies, making this integration type ubiquitous in modern SaaS stacks.
Best suited for:
- SaaS-heavy stacks where business processes need to stay synchronized
- Syncing Salesforce with a data warehouse
- Pushing enriched data back to a CRM
Key strength: Real-time operational sync, widely supported by modern SaaS platforms, and straightforward to implement with iPaaS tools.
Main limitation: API rate limits (e.g., Slack's 1 request/second), versioning changes, and vendor dependency can make these integrations brittle at scale.
How to Choose the Right Type of Data Integration
The "best" type is always relative to your specific architecture, data freshness requirements, team capabilities, and downstream use case. Popularity or familiarity are poor selection criteria.
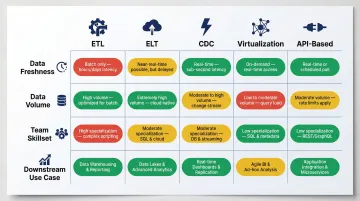
Use this table as a quick reference when evaluating your options:
| Factor | Decision Signal | Best-Fit Approach |
|---|---|---|
| Data freshness | Hours or days of lag acceptable | ETL/ELT batch pipelines |
| Data freshness | Minutes or seconds required | CDC or API-based integration |
| Volume & infrastructure | High-volume analytics on cloud | ELT |
| Volume & infrastructure | Legacy/on-premise with complex transforms | ETL |
| Volume & infrastructure | No data movement preferred | Virtualization |
| Team skillset | Strong SQL and dbt proficiency | ELT |
| Team skillset | Minimal engineering overhead needed | Application-based integration (note: vendor dependency) |
| Downstream use case | Analytics and BI with a central warehouse | ETL/ELT |
| Downstream use case | Operational app connectivity | API-based integration |
| Downstream use case | Compliance-constrained environment | Virtualization |
Common mistake: Choosing the most complex or technically impressive option when a simpler approach would fully satisfy requirements. Over-engineering integration pipelines is one of the most common causes of data team burnout and technical debt.
Data Integration Best Practices
Establish Data Ownership and Documentation Upfront
Every integrated dataset should have a clear owner, a defined schema, and documented transformations. Without this, pipelines become black boxes that no one trusts.
Tools built on governed context — like dbt documentation — make this easier and allow AI-powered analytics tools to reason accurately over your data. Sylus, for example, grounds all analysis in dbt models and documentation so natural language queries return results tied to validated, team-approved definitions.
Monitor Pipeline Health Continuously, Not Reactively
Failed or silently degraded pipelines are a leading cause of bad downstream data. Organizations experience an average of 67 data incidents per month, with an average time to resolution of 15 hours per incident.
Implement alerting on:
- Row count anomalies
- Schema drift
- Latency breaches
- Data freshness violations

Catch these issues before users report data problems.
Design for Schema Evolution
Source systems change their data structures without warning. Build integration pipelines with defensive schema handling — nullable fields, version-tolerant parsers — to prevent cascading failures when upstream apps update.
Modern ELT tools like dbt support schema evolution parameters (such as on_schema_change) that allow pipelines to continue running even when source schemas change.
Avoid Replicating Data Unnecessarily
Each additional copy of data is a consistency liability. To keep things manageable:
- Consolidate to the fewest integration layers that serve the downstream use case
- Prefer transformation-in-warehouse (ELT) approaches to reduce intermediate copies
- Audit existing pipelines periodically to retire redundant data stores
Frequently Asked Questions
What are the different types of data integration?
The five main types are ETL (extract, transform, load), ELT (extract, load, transform), Change Data Capture (CDC), Data Virtualization, and Application/API-Based Integration. Each suits different latency, volume, and infrastructure needs.
Is ETL the same as API?
No. ETL is a data pipeline pattern used to move data into a warehouse for analytics, while an API is a communication interface that allows applications to exchange data in real time. They serve different purposes and are often used together in a modern data stack.
What is the difference between ETL and ELT?
ETL transforms data before loading it into the destination, while ELT loads raw data first and transforms it inside the warehouse. ELT is better suited to cloud-native stacks with high compute availability.
What are the benefits of data integration?
Data integration delivers unified data visibility, faster reporting, reduced data silos, and the ability to power AI-driven analytics across every team and system.
When should I use Change Data Capture instead of ETL?
Use CDC when data freshness requirements are under a few minutes, or when only incremental changes (not full table loads) should be moved. ETL batch loads are sufficient for daily or hourly reporting needs.
What is data virtualization and when does it make sense?
Data virtualization creates a query layer over source systems without physically moving data. It makes sense when compliance restrictions prevent copying data, or when a unified view is needed quickly without building a full pipeline.


