
Introduction
Modern organizations run data across dozens of disconnected systems — CRMs, ERPs, data warehouses, cloud apps, and spreadsheets. When customer data lives in Salesforce, transactions sit in Stripe, inventory is tracked in NetSuite, and analytics run in Snowflake, keeping data consistent across all of them becomes expensive and error-prone.
Gartner estimates that poor data quality costs organizations at least $12.9 million annually. In severe cases, Unity Technologies lost $110 million in revenue after corrupted data ingestion broke their predictive algorithms.
Data synchronization tools solve this by keeping data consistent and current across all systems, automatically propagating inserts, updates, and deletes without manual exports or re-entry. Choosing the right tool comes down to four factors:
- Use case — real-time streaming vs. scheduled batch processing
- Scale — thousands of records per sync vs. millions per second
- Architecture — cloud-native, on-premise, or hybrid deployments
- Connector coverage — whether the tool supports your specific sources and destinations
Key Takeaways
- Data synchronization tools maintain consistent, up-to-date data across multiple systems in real time or on a schedule
- The best tool depends on your use case: streaming, cloud migration, ELT pipelines, or open-source flexibility—each category has a clear front-runner
- Key selection criteria include latency, connector coverage, deployment model, and compliance requirements
- Once data is synchronized, AI-powered analytics tools like Sylus connect directly to unified data sources and let teams query in plain English—turning sync infrastructure into actionable business insights
What Is Data Synchronization?
Data synchronization is the ongoing process of detecting changes in one data source and propagating them to all connected systems to maintain consistency. Unlike one-time data migration or manual exports, synchronization is continuous and automated.
When a customer updates their address in your CRM, that change flows automatically to your billing system, order fulfillment database, and every other connected platform—without anyone triggering it manually.
Sync Modes: Real-Time vs. Batch
Data synchronization operates in two primary modes:
- Real-time/continuous sync uses event-driven architectures to propagate changes with low latency (seconds or milliseconds). This is essential for operational use cases like fraud detection, inventory management, and real-time dashboards.
- Batch/scheduled sync processes changes at regular intervals (hourly, daily) and is more resource-efficient but introduces lag. This works well for analytical workloads where near-instant updates aren't critical.

How Synchronization Differs from Related Concepts
Data replication is typically unidirectional, copying data from source to destination for availability or backup. Data integration is a broader discipline focused on unifying disparate formats and sources into a single system.
Data synchronization sits between these two: it's bidirectional (or multi-directional), ongoing, and focused on maintaining consistency as changes occur across multiple systems simultaneously.
The 10 Best Data Synchronization Tools in 2026
These tools were selected based on reliability, breadth of connector support, deployment flexibility, and suitability for modern data stacks—ranging from open-source to enterprise-grade platforms.
Apache Kafka
Apache Kafka is an open-source distributed event streaming platform originally built by LinkedIn and now maintained by the Apache Software Foundation. It's widely used for high-throughput real-time data pipelines and microservices architectures, with over 80% of the Fortune 100 relying on it. Kafka's fault-tolerant pub/sub messaging architecture scales horizontally to process millions of events per second—Confluent Cloud's Kora engine handles over 3 trillion messages per day with consistent low latencies at 200,000 messages per second.
Kafka's distributed commit log architecture—combined with Kafka Connect for source/sink connectors and Schema Registry for enforcing data contracts—makes it the foundation for real-time sync across heterogeneous systems.
| Criteria | Details |
|---|---|
| Best For | Real-time event streaming, microservices data pipelines, log aggregation |
| Key Features | Distributed commit log, Kafka Connect for source/sink connectors, Schema Registry |
| Deployment | Self-hosted, Confluent Cloud (managed), Amazon MSK |
Debezium
Debezium is an open-source Change Data Capture (CDC) platform built on top of Apache Kafka that reads database transaction logs to capture row-level changes with minimal impact on source systems. Unlike polling-based methods that repeatedly query databases, Debezium uses log-based CDC—reading MySQL's binlog, PostgreSQL's WAL, or MongoDB's oplog—to capture inserts, updates, and deletes without performance overhead on the source database.
What separates Debezium from polling alternatives:
- Zero-polling overhead via direct transaction log reads
- Supports MySQL, PostgreSQL, MongoDB, SQL Server, and Oracle
- Near-real-time propagation with exactly-once delivery guarantees
- Over 12,500 GitHub stars, reflecting broad community adoption
| Criteria | Details |
|---|---|
| Best For | CDC from relational and NoSQL databases, event-driven microservices |
| Key Features | Transaction log reading, exactly-once delivery, Kafka integration |
| Deployment | Self-hosted (open-source), integrates with Confluent Platform |
Airbyte
Airbyte is an open-source data integration platform with a rapidly expanding connector catalog covering 700+ SaaS tools, databases, and APIs. The platform's Connector Development Kit (CDK)—available in Python and low-code formats—allows data engineers to build production-grade custom connectors quickly, driving its massive connector growth.
The open-source core lowers the barrier to entry, and Airbyte Cloud offers a managed version for teams that want to skip infrastructure management entirely. The platform also integrates with dbt Cloud, letting users automatically trigger dbt transformations immediately after a sync completes.
| Criteria | Details |
|---|---|
| Best For | ELT pipelines from SaaS and databases into data warehouses |
| Key Features | 700+ connectors, Connector Development Kit (CDK), dbt transformation support |
| Deployment | Self-hosted (open-source via Docker/Kubernetes) or Airbyte Cloud (managed SaaS) |
Fivetran
Fivetran is a fully managed ELT platform purpose-built for automated data pipeline creation, known for its fully maintained connectors that automatically adapt to schema and API changes without manual intervention. The platform operates on a consumption-based pricing model measured in Monthly Active Rows (MAR)—charging only for distinct primary keys updated per month, regardless of how many times each row is updated.
Zero-maintenance connectors, automated schema drift handling (a net-additive approach that soft-deletes removed columns to prevent pipeline breakages), and deep integrations with Snowflake, BigQuery, Databricks, and Redshift make it the preferred choice for analytics teams that prioritize reliability without pipeline babysitting. Fivetran guarantees a 99.9% uptime SLA.
| Criteria | Details |
|---|---|
| Best For | Automated ELT into cloud data warehouses, analytics teams |
| Key Features | Auto-maintained connectors, schema drift handling, data freshness SLAs |
| Pricing | Consumption-based (Monthly Active Rows); Free tier up to 500,000 MAR, then Standard/Enterprise/Business Critical tiers |
AWS DataSync
AWS DataSync is a managed data transfer service from Amazon Web Services that automates moving large volumes of data between on-premises storage and AWS services (S3, EFS, FSx) or between AWS storage services. A single DataSync task can fully utilize a 10 Gbps network link, making it ideal for large-scale cloud migration and hybrid storage synchronization scenarios.
For AWS-centric teams, the combination is hard to beat:
- TLS 1.3 encryption in transit with built-in checksum verification
- Bandwidth throttling to control network impact during transfers
- Native integration across the full AWS storage ecosystem
- Agent-based deployment supports VMware, KVM, and Hyper-V on-premises sources
| Criteria | Details |
|---|---|
| Best For | Large-scale cloud migration, on-premises to AWS storage sync |
| Key Features | Automated data validation, encryption in transit/at rest, scheduling, 10 Gbps throughput |
| Deployment | AWS managed service; agent-based for on-premises sources (VMware, KVM, Hyper-V) |
Azure Data Factory
Azure Data Factory (ADF) is Microsoft's cloud-based ETL and data integration service that orchestrates data movement and transformation across on-premises, cloud, and SaaS data sources within the Azure ecosystem. The platform features 90+ built-in connectors and provides a visual drag-and-drop pipeline designer that empowers data engineers without requiring code.
Deep native integration with Azure services (Synapse Analytics, Blob Storage, SQL Database), mapping data flows that execute on scaled-out Apache Spark clusters without infrastructure management, and flexible scheduled or event-based triggers make it the default choice for teams already running on the Microsoft stack.
| Criteria | Details |
|---|---|
| Best For | Azure-centric organizations, hybrid ETL/ELT orchestration |
| Key Features | Visual pipeline designer, 90+ connectors, mapping data flows, triggers |
| Deployment | Azure managed service (cloud-native) |
Talend
Talend (now part of Qlik following a May 2023 acquisition) is an enterprise data integration platform offering both open-source and commercial editions, with a visual ETL design environment and connectors for cloud platforms, databases, and SaaS applications. Following the acquisition, Qlik discontinued the open-source Talend Open Studio effective January 31, 2024, shifting focus entirely to commercial offerings.
Built-in data quality and governance capabilities—including the proprietary Talend Trust Score—plus support for both batch and streaming pipelines distinguish Talend in complex enterprise environments where strict data governance is non-negotiable. Cloud integrations with Snowflake and Azure are included in commercial tiers.
| Criteria | Details |
|---|---|
| Best For | Enterprise ETL, data quality enforcement, hybrid environments |
| Key Features | Visual ETL designer, data quality/profiling, Talend Trust Score, cloud integration |
| Deployment | On-premises, cloud, or hybrid (commercial tiers only after Open Studio discontinuation) |
Informatica
Few platforms match Informatica's breadth in enterprise data management. Its cloud-native offering—the Intelligent Data Management Cloud (IDMC)—covers data quality, master data management, governance, and integration in a single platform. The company has been named a Leader in the Gartner Magic Quadrant for Data Integration Tools for 20 consecutive years, including 2024 and 2025.
The CLAIRE AI engine automates data discovery, pipeline building, and quality remediation using metadata intelligence. With 50,000+ metadata-aware connections, robust data lineage, and enterprise-grade compliance support, it's the top choice for regulated industries and F1000 enterprises.
| Criteria | Details |
|---|---|
| Best For | Enterprise data governance, complex multi-cloud integration, regulated industries |
| Key Features | CLAIRE AI engine, data lineage, Master Data Management (MDM), 50,000+ connections |
| Deployment | Cloud (IDMC SaaS), hybrid, on-premises |
MuleSoft
MuleSoft (a Salesforce company, acquired in 2018) is an integration platform that uses API-led connectivity to connect applications, data sources, and devices—commonly used for enterprise application integration (EAI) and B2B data sync. The Anypoint Platform uniquely combines Integration Platform as a Service (iPaaS) with full API lifecycle management in a single platform.
DataWeave—a functional programming language for data transformation—combined with Anypoint Exchange's 1,500+ pre-built connectors and templates and unified API management makes MuleSoft the practical choice for organizations synchronizing data across internal apps, partner systems, and cloud services simultaneously.
| Criteria | Details |
|---|---|
| Best For | API-led enterprise integration, Salesforce-centric ecosystems |
| Key Features | Anypoint Platform, pre-built connectors, API management, DataWeave transformations |
| Deployment | Cloud, hybrid, on-premises |
Dell Boomi
Dell Boomi is a cloud-native iPaaS (Integration Platform as a Service) that connects applications and data sources through a low-code visual interface, with AI-assisted mapping and a library of pre-built integration components. The platform utilizes a flexible runtime engine called the Atom, which can be deployed as Boomi-hosted runtime clouds or installed on-premises behind a firewall for hybrid architectures.
The "Suggest" AI feature accelerates field mapping by drawing on millions of anonymized mappings logged by the Boomi community—reducing manual mapping effort on new integrations. The AtomSphere platform handles both B2B/EDI integration and standard application integration, covering a wider range of use cases than most comparable iPaaS platforms.
| Criteria | Details |
|---|---|
| Best For | Low-code enterprise integration, B2B/EDI sync, hybrid environments |
| Key Features | AI-assisted mapping (Suggest), pre-built connectors, Atom runtime, EDI support |
| Deployment | Cloud-hosted Atoms or on-premises Atoms (hybrid) |
How to Choose the Right Data Synchronization Tool
The most common mistake teams make is selecting a tool based on brand recognition or peer recommendations without mapping tool capabilities to their specific latency, volume, and ecosystem requirements—leading to overengineered or underperforming pipelines. Here's how to evaluate properly:
Technical Criteria
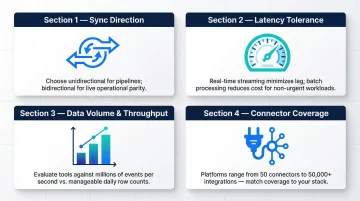
- Sync direction: One-way replication (source to destination) suits most ELT tools; bidirectional sync—where changes flow both ways—is more common in iPaaS platforms. Confirm which your use case actually requires before shortlisting.
- Latency tolerance: Real-time streaming (Kafka, Debezium) delivers sub-second latency but demands infrastructure expertise. Scheduled batch sync (Fivetran, Talend) introduces lag but is simpler to operate and more cost-effective for analytical workloads.
- Data volume and throughput: Processing millions of events per second points to Kafka. For hundreds of thousands of rows per day across SaaS apps, Fivetran or Airbyte will suffice.
- Connector coverage: Verify your specific sources and destinations are natively supported. Airbyte covers 700+ connectors; Informatica reaches 50,000+ metadata-aware connections. Neither matters if your critical systems aren't on the list.
Operational Criteria
- Deployment model: Managed SaaS (Fivetran, Airbyte Cloud) reduces operational burden but can create vendor lock-in. Self-hosted open-source (Kafka, Debezium, Airbyte OSS) gives more control but requires dedicated engineering resources.
- Security and compliance: Enterprise buyers should verify SOC 2 Type II, HIPAA, and GDPR compliance. Fivetran, Informatica, and Talend maintain these certifications explicitly.
- Total cost of ownership: Consumption-based pricing (Fivetran's MAR model) aligns cost with usage but can produce budget overruns without governance. Also factor in connector maintenance hours for open-source options. Talend's sunsetting of Open Studio in January 2024 is a clear example of the ongoing burden unsupported open-source integration carries.
Turning Sync into Insights
Synchronized data is only valuable when teams can query and act on it. Sylus connects directly to synced data sources in Snowflake, BigQuery, or Databricks and lets users query, visualize, and share findings in plain English. All analysis is grounded in dbt models and documentation, so non-technical users can explore data independently without writing SQL or waiting on data engineers.
Conclusion
The right data synchronization tool depends on the intersection of your architecture (cloud-native vs. hybrid), team maturity (managed SaaS vs. open-source), and data requirements (real-time streaming vs. scheduled batch). No single tool wins for every use case: Kafka dominates high-throughput event streaming, Fivetran excels at zero-maintenance ELT into cloud warehouses, and Informatica leads in complex enterprise governance scenarios.
Before committing, run a proof of concept with 1-2 shortlisted tools against your actual data volumes and sources. Assess scalability and connector maintenance burden over the long term rather than just initial setup ease. By 2026, Gartner projects that 80% of organizations seeking to scale AI will fail because they haven't modernized their data governance and infrastructure—which means your synchronization tool choice directly shapes whether your AI initiatives succeed or stall.
Once your data is synchronized and consistent across systems, the next bottleneck is usually access—getting answers out of that data without routing every question through an engineer. Sylus connects to your data sources and lets your team ask questions in plain English, returning validated analysis grounded in your actual data models. Start exploring at sylus.ai/get-started.
Frequently Asked Questions
What is database synchronization?
Database synchronization is the process of ensuring two or more databases contain identical, up-to-date data by automatically propagating inserts, updates, and deletes from a source database to one or more target databases.
What are common data synchronization tools?
Common tools include Apache Kafka, Debezium, Airbyte, Fivetran, AWS DataSync, Talend, and Informatica. The best choice depends on your use case: streaming vs. batch, open-source vs. enterprise, and whether you need ELT pipelines or event-driven architectures.
What's the best database integration tool?
There is no single "best" tool. Fivetran and Airbyte lead for modern ELT into cloud warehouses, Informatica and Talend excel in enterprise complexity and governance, and Apache Kafka dominates high-throughput real-time streaming scenarios.
What is an example of data synchronization?
When a customer updates their address in an e-commerce platform, data synchronization ensures that change is automatically propagated to the CRM, billing system, and order fulfillment database without manual re-entry, keeping all systems consistent in real time.
What is the difference between data synchronization and data replication?
Data replication is typically unidirectional—copying data from source to destination for availability or backup. Data synchronization is bidirectional and ongoing, keeping multiple systems mutually consistent as changes occur on either side.
How do I choose the right data synchronization tool for my business?
Evaluate these factors before selecting a tool:
- Latency needs: Real-time streaming vs. scheduled batch
- Connector coverage: Does it support your specific sources and destinations?
- Deployment model: Managed cloud vs. self-hosted
- Compliance: SOC 2, HIPAA, or GDPR requirements
- Total cost of ownership: Factor in engineering hours for connector maintenance


