
Introduction
Modern businesses generate data every second (clickstreams, IoT sensors, transactions, user events)—and the window to act on it is measured in milliseconds, not days. The shift from batch reporting to real-time analytics is forcing teams to rethink their entire data stack.
According to IDC, global data generation will reach 221 zettabytes by 2026, with the world currently producing 3.81 petabytes every single second. Delayed insights directly erode revenue: Amazon found that every 100 milliseconds of latency cost them 1% in sales.
Choosing the wrong platform leads to months of wasted engineering effort. This guide covers the top real-time analytics platforms and tools, what separates them, and how to choose the right one for your team's needs and technical maturity.
Key Takeaways
- Real-time analytics platforms process and surface insights as events occur—eliminating batch reporting lag
- The market spans AI-native analytics layers, streaming infrastructure (Kafka, Flink), OLAP databases (ClickHouse), and cloud-managed services (Amazon Kinesis)
- Choosing the right platform comes down to query latency, ingestion throughput, scalability, and total cost of ownership
- AI-powered platforms like Sylus let business users query live data in plain English—no SQL or analyst bottleneck required
What Is a Real-Time Analytics Platform?
Real-time analytics is the process of collecting, processing, and querying data within milliseconds to seconds of generation, unlike batch analytics that operates on hours-old snapshots. Gartner distinguishes between two modes: on-demand (query-triggered) and continuous (proactive alerts and responses).
A real-time analytics stack typically spans four layers:
- Data ingestion layer — Event streams, CDC, APIs
- Stream processing engine — Real-time transformations and aggregations
- Analytical storage or query layer — OLAP databases or query engines
- Presentation/delivery layer — Dashboards, APIs, alerts
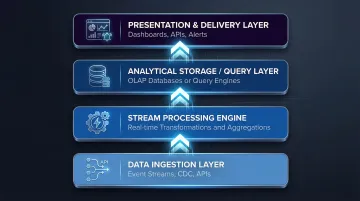
Each layer must handle data at speed — which helps explain why investment in this space has accelerated sharply. The global streaming analytics market was valued at $23.4 billion in 2023 and is projected to reach $128.4 billion by 2030, growing at a 28.3% CAGR according to Grand View Research. At that growth rate, real-time decision-making has moved from competitive advantage to operational baseline for most data teams.
The platforms below represent the leading options across these layers.
Top Real-Time Analytics Platforms & Tools
These platforms were selected based on performance benchmarks, ecosystem adoption, ease of deployment, and enterprise readiness. They cover different layers of the real-time data stack — from streaming infrastructure and stream processing to OLAP databases and AI-powered querying — so the right choice depends on where your bottleneck actually sits.
Sylus
Sylus is an AI-powered analytics platform that lets data teams and business users query any connected data source using plain English—think ChatGPT, but trained on your business's data. It serves fast-growing startups through F1000 enterprises, including OpenAI.
The core differentiator is governed context. Every analysis is grounded in your dbt models and dbt documentation, so outputs are validated against your actual data definitions — not hallucinated. From there, Sylus generates entire dashboards automatically, supports Slack-based querying, schedules AI-generated reports, and offers self-hosted deployment for teams with strict data residency requirements.
| Category | Details |
|---|---|
| Key Features | Natural language querying, auto-generated dashboards, AI-driven data summaries, Slack integration, scheduled reports, spike alerts, embedded analytics sharing |
| Security & Compliance | SOC 2 Type II certified, HIPAA compliant, self-hosted deployment available, no model training on customer data |
| Pricing & Deployment | Unlimited seats with usage-based pricing; cloud and self-hosted options available |
Apache Kafka
Apache Kafka is an open-source distributed event streaming platform originally developed at LinkedIn and now maintained by the Apache Software Foundation. It has become the standard backbone for high-throughput, fault-tolerant data pipelines across thousands of enterprises — trusted by over 80% of the Fortune 100.
Kafka's key architectural advantage is producer-consumer decoupling: multiple downstream analytics systems can consume the same event stream simultaneously without coordination. Its durability, partition-based scalability, and exactly-once semantics (introduced in KIP-98) explain why it remains the most widely adopted streaming infrastructure layer in production.
In vendor benchmarks, Kafka achieved 605 MB/s throughput with 5 ms p99 latency under 200 MB/s load.
| Category | Details |
|---|---|
| Key Features | Distributed publish-subscribe messaging, high-throughput ingestion, topic partitioning, stream-to-stream joins via Kafka Streams |
| Best For | Teams building streaming data pipelines that feed multiple downstream analytics consumers; microservice event buses |
| Deployment | Open-source (self-managed) or managed via Confluent Cloud, AWS MSK, or other cloud providers |
ClickHouse
ClickHouse is an open-source columnar OLAP database designed for high-performance analytical queries on large event datasets. It is used by companies like Cloudflare, Uber, and eBay for real-time reporting workloads.
Performance at this scale comes down to how ClickHouse handles indexing. Unlike traditional B-Tree databases that index every row, its MergeTree storage engine uses a sparse index — storing one mark per granule (8,192 rows by default) — which keeps the entire index in RAM and enables sub-second query latency on billions of rows.
Beyond indexing, ClickHouse supports incremental materialized views that update automatically as data arrives and achieves extremely high ingestion rates through LSM-like background merging.
| Category | Details |
|---|---|
| Key Features | Columnar storage with MergeTree engine, sparse indexes, incremental materialized views, projections for multi-pattern queries |
| Best For | Teams with SQL and database modeling expertise who need fast exploratory OLAP over continuously ingested event streams |
| Deployment | Open-source (self-managed) or ClickHouse Cloud (managed SaaS) |
Amazon Kinesis
Amazon Kinesis is a fully managed, cloud-native real-time data streaming service from AWS that enables teams to collect, process, and analyze streaming data at any scale without managing infrastructure.
The primary draw is native AWS integration. Teams can connect Kinesis directly to Lambda, S3, Redshift, and OpenSearch — building complete streaming pipelines without leaving the AWS ecosystem. Kinesis Data Analytics supports both SQL and Apache Flink for in-stream processing, while Kinesis Data Streams handles gigabytes per second from diverse sources.
Capacity scales on demand: each shard supports up to 1 MB/sec or 1,000 records/sec for writes, with on-demand scaling reaching 10 GB/s in select regions.
| Category | Details |
|---|---|
| Key Features | Managed streaming ingest, Kinesis Data Analytics (Flink), native AWS integrations, real-time dashboards via Kinesis Data Firehose to BI tools |
| Best For | AWS-native teams seeking a managed streaming solution without infrastructure operations; fraud detection, clickstream, and IoT workloads |
| Deployment | Fully managed cloud service; consumption-based pricing on AWS |
Apache Flink
Apache Flink is an open-source stateful stream processing engine built for complex event-time computations at massive scale. It is used by companies like Alibaba and Netflix for large-scale stream processing pipelines, with Alibaba processing billions of events per second during its Double 11 shopping festival.
Two capabilities set Flink apart for production workloads. First, exactly-once semantics via distributed checkpointing make it suitable for financial and compliance-grade pipelines where dropped or duplicate events aren't acceptable. Second, event-time watermarks handle late-arriving and out-of-order data correctly — a requirement that simpler streaming tools routinely get wrong.
In practice, Flink typically serves as a transformation layer: enriching and aggregating streams before they land in an analytical serving database like ClickHouse or Redshift.
| Category | Details |
|---|---|
| Key Features | Stateful stream processing, event-time windowing, exactly-once semantics, Table API and SQL support, Kubernetes-native deployment |
| Best For | Teams needing complex stream transformations, joins, and aggregations before loading results into analytical databases or dashboards |
| Deployment | Open-source (self-managed on Kubernetes/YARN) or managed via Confluent, AWS, or Ververica Platform |
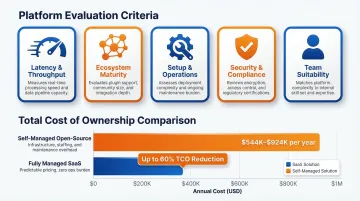
How We Chose These Real-Time Analytics Platforms
Tools were assessed across five dimensions:
- Latency and throughput capabilities — How quickly can the system process and query data?
- Ecosystem maturity and production adoption — Is this proven at scale in production environments?
- Ease of setup and operational burden — What's the total engineering cost to run this?
- Enterprise security and compliance posture — Does it meet SOC 2, HIPAA, and other certifications?
- Suitability across team profiles — Is this for infrastructure engineers or business analysts?
A common mistake teams make: selecting a tool based on raw benchmark performance without accounting for the full operational cost of running it in production. Self-managing open-source streaming infrastructure costs between $544K and $924K annually for a mid-sized deployment, driven by the need for 1.5–2.0 dedicated engineering FTEs and high-cardinality observability metrics. Fully managed SaaS offerings can reduce TCO by up to 60%.
Cost isn't the only selection trap. The category a tool belongs to matters as much as its performance specs — teams confusing streaming infrastructure (Kafka, Flink) with analytics delivery platforms will over-engineer their stack. The right selection aligns the tool's design purpose with the team's actual requirement: data pipeline backbone, OLAP query engine, or analytics consumption layer.
Compliance certifications (SOC 2, HIPAA), self-hosted deployment options, and unlimited-seat pricing models are now table-stakes for regulated industries and fast-growing teams that can't absorb per-seat costs at scale. According to Gartner, 46% of software buyers now rank security certifications as a top vendor selection criterion.
Conclusion
No single real-time analytics tool fits every team—the best choice depends on where in the stack your bottleneck lives: ingestion, processing, storage, or analytics delivery. Evaluate total cost of ownership honestly, including engineering time for configuration, index tuning, pipeline maintenance, and schema management—not just licensing fees.
If the bottleneck is analytics delivery — getting answers to non-technical stakeholders without engineering overhead — Sylus addresses that directly. It connects to your existing data sources and lets your team query, build dashboards, and share insights in plain English, without touching the underlying pipeline.
Frequently Asked Questions
What is a real-time analytics platform?
A real-time analytics platform is a system that ingests, processes, and delivers insights within milliseconds to seconds of data generation—enabling businesses to act on live information rather than historical snapshots. Most platforms support two modes: on-demand (query-triggered) and continuous (proactive alerts).
What are the 4 types of analytics?
The four types are descriptive (what happened), diagnostic (why it happened), predictive (what will happen), and prescriptive (what should be done). Real-time platforms compress that progression—cutting the gap between data generation and a decision worth acting on.
What is the difference between real-time analytics and batch analytics?
Batch analytics processes accumulated data at scheduled intervals (minutes to hours of latency), while real-time analytics processes data continuously as it arrives (milliseconds to seconds of latency). Real-time is better suited for fraud detection, live personalization, and operational monitoring.
What are the key features to look for in a real-time analytics platform?
Prioritize these when evaluating options:
- Low query latency and high ingestion throughput
- Easy integration with your existing data sources
- Security certifications (SOC 2, HIPAA) for compliance-sensitive environments
- Scalability under concurrent query load
- Low operational overhead — how much engineering time it actually requires
How does AI improve real-time analytics?
AI layers—like natural language querying, automated anomaly detection, and AI-generated summaries—reduce the time between data availability and business decision-making. Non-technical users can ask questions in plain English instead of writing SQL, and anomaly alerts mean critical patterns get flagged before anyone thinks to check a dashboard.


